Table of Contents
Introduction
Here at Puget Systems, we do a lot of hardware evaluation and testing that we freely publish and make available to the public. At the moment, most of our testing is focused on content creation workflows like video editing, photography, and game development. However, we’re currently evaluating AI/ML-focused benchmarks to implement into our testing suite to better understand how hardware choices affect the performance of these workloads. One of these benchmarks comes from NVIDIA in the form of TensorRT-LLM, and in this post, I’d like to talk about TensorRT-LLM and share some preliminary inference results from a selection of NVIDIA GPUs.
Here’s how TensorRT-LLM is described: “TensorRT-LLM provides users with an easy-to-use Python API to define Large Language Models (LLMs) and build TensorRT engines that contain state-of-the-art optimizations to perform inference efficiently on NVIDIA GPUs. TensorRT-LLM also contains components to create Python and C++ runtimes that execute those TensorRT engines.“
Based on the name alone, it’s safe to assume that TensorRT-LLM performance benchmarks will scale closely with Tensor Core performance. Since all the GPUs I tested feature 4th-generation Tensor Cores, comparing the Tensor Core count per GPU should give us a reasonable metric to estimate the performance for each model. However, as the results will soon show, there is more to an LLM workload than raw computational power. The width of a GPU’s memory bus, and more holistically, the overall memory bandwidth, is an important variable to consider when selecting GPUs for machine learning tasks.
| GPU | VRAM (GB) | Tensor Cores | Memory Bus Width | Memory Bandwidth |
|---|---|---|---|---|
| NVIDIA GeForce RTX 4090 | 24 | 512 | 384-bit | ~1000 GB/s |
| NVIDIA GeForce RTX 4080 SUPER | 16 | 320 | 256-bit | ~735 GB/s |
| NVIDIA GeForce RTX 4080 | 16 | 304 | 256-bit | ~715 GB/s |
| NVIDIA GeForce RTX 4070 Ti SUPER | 16 | 264 | 256-bit | ~670 GB/s |
| NVIDIA GeForce RTX 4070 Ti | 12 | 240 | 192-bit | ~500 GB/s |
| NVIDIA GeForce RTX 4070 SUPER | 12 | 224 | 192-bit | ~500 GB/s |
| NVIDIA GeForce RTX 4070 | 12 | 184 | 192-bit | ~500 GB/s |
| NVIDIA GeForce RTX 4060 Ti | 8 | 136 | 128-bit | ~290 GB/s |
NVIDIA was kind enough to send us a package for TensorRT-LLM v0.5.0 containing a number of scripts to simplify the installation of the dependencies, create virtual environments, and properly configure the environment variables. This is all incredibly helpful when you expect to run benchmarks on a great number of systems! Additionally, these scripts are intended to set TensorRT-LLM up on Windows, making it much easier for us to implement into our current benchmark suite.
However, although TensorRT-LLM supports tensor-parallelism and pipeline parallelism, it appears that multi-GPU usage may be restricted to Linux, as the documentation states that “TensorRT-LLM is supported on bare-metal Windows for single-GPU inference.” Another limitation of this tool is that we can only use it to test NVIDIA GPUs, leaving out CPU inference, AMD GPUs, and Intel GPUs. Although considering the current state of NVIDIA’s dominance in this field, there’s still value in a tool for comparing the capabilities and relative performance of NVIDIA GPUs.
Another consideration is that, like TensorRT for StableDiffusion, an engine must be generated for each LLM model and GPU combination. However, I was surprised to find that an engine generated for one GPU did not prevent the benchmark from being completed when used with another GPU. Using mismatched engines did occasionally impact performance depending on the test variables, so as expected, the best practice is to generate a new engine for each GPU. I also suspect the output text generated would likely be meaningless when an incorrect engine is used, but these benchmarks don’t display any output.
Despite all these caveats, we look forward to seeing how different GPUs perform with this LLM package with TensorRT optimizations. We will start by only looking at NVIDIA’s GeForce line, but we hope to expand this testing to include the Professional RTX cards and a range of other LLM packages in the future.
Test Setup
The TensorRT-LLM package we received was configured to use the Llama-2-7b model, quantized to a 4-bit AWQ format. Although TensorRT-LLM supports a variety of models and quantization methods, I chose to stick with this relatively lightweight model to test a number of GPUs without worrying too much about VRAM limitations.
For each row of variables below, I ran five consecutive tests per GPU and averaged the results.
| input length | output length | batch size |
| 100 | 100 | 1 |
| 100 | 100 | 8 |
| 2048 | 512 | 1 |
| 2048 | 512 | 8 |
Results
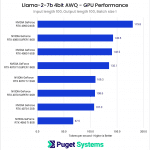
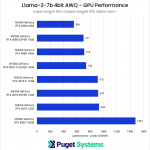

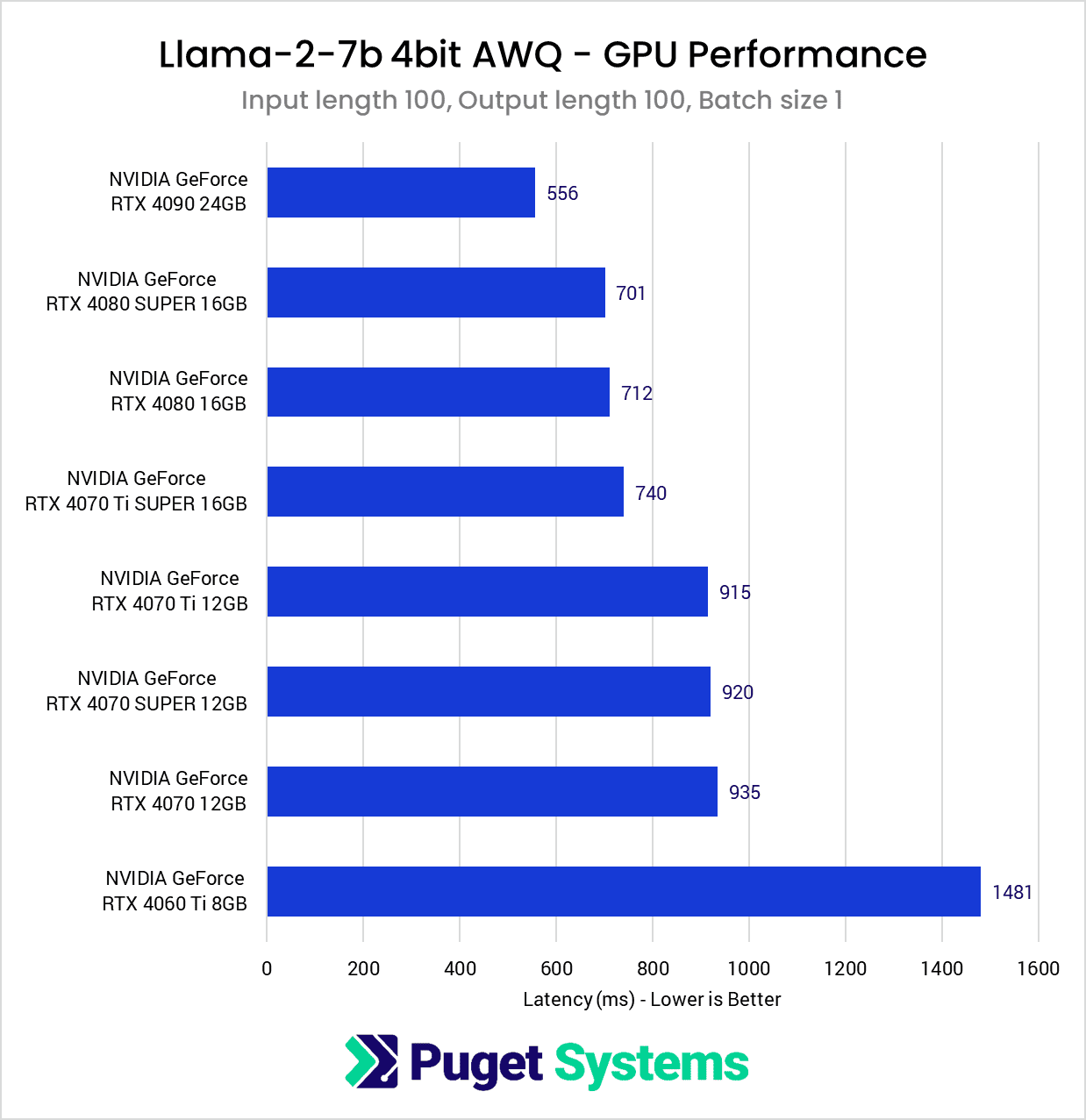
System Image
Overall, the performance results fall right in line with expectations based on the Tensor Core count of each card. However, we also see the performance between cards featuring the same memory bus width is quite close, despite the relative differences in Tensor Core count. The most notable example of this occurred between the 4070 and 4070 Ti. Although the 4070 Ti has roughly 30% more Tensor Cores than the base 4070, this only translated into a difference of about two tokens per second.
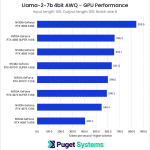
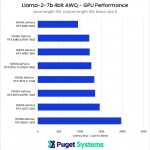


System Image
Using the same input and output length of 100, but increasing the batch size to 8, we start to see a slightly wider spread across the cards that were previously grouped by their relative memory bandwidth, causing the results to trend towards tracking more closely with Tensor Cores.
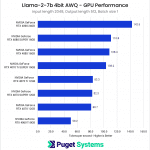

System Image
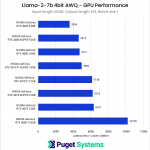
Increasing the input and output lengths to the maximum recommended by NVIDIA for this particular model, we once again find that with a batch size of one, the results trend closely with the available memory bandwidth. It’s slightly less pronounced than with the smaller “100,100” tests, and I suspect that the larger context requires more calculations, providing a greater benefit to having more Tensor Cores available. Despite that, it’s clear that memory bandwidth still has a major role in this test.
System Image
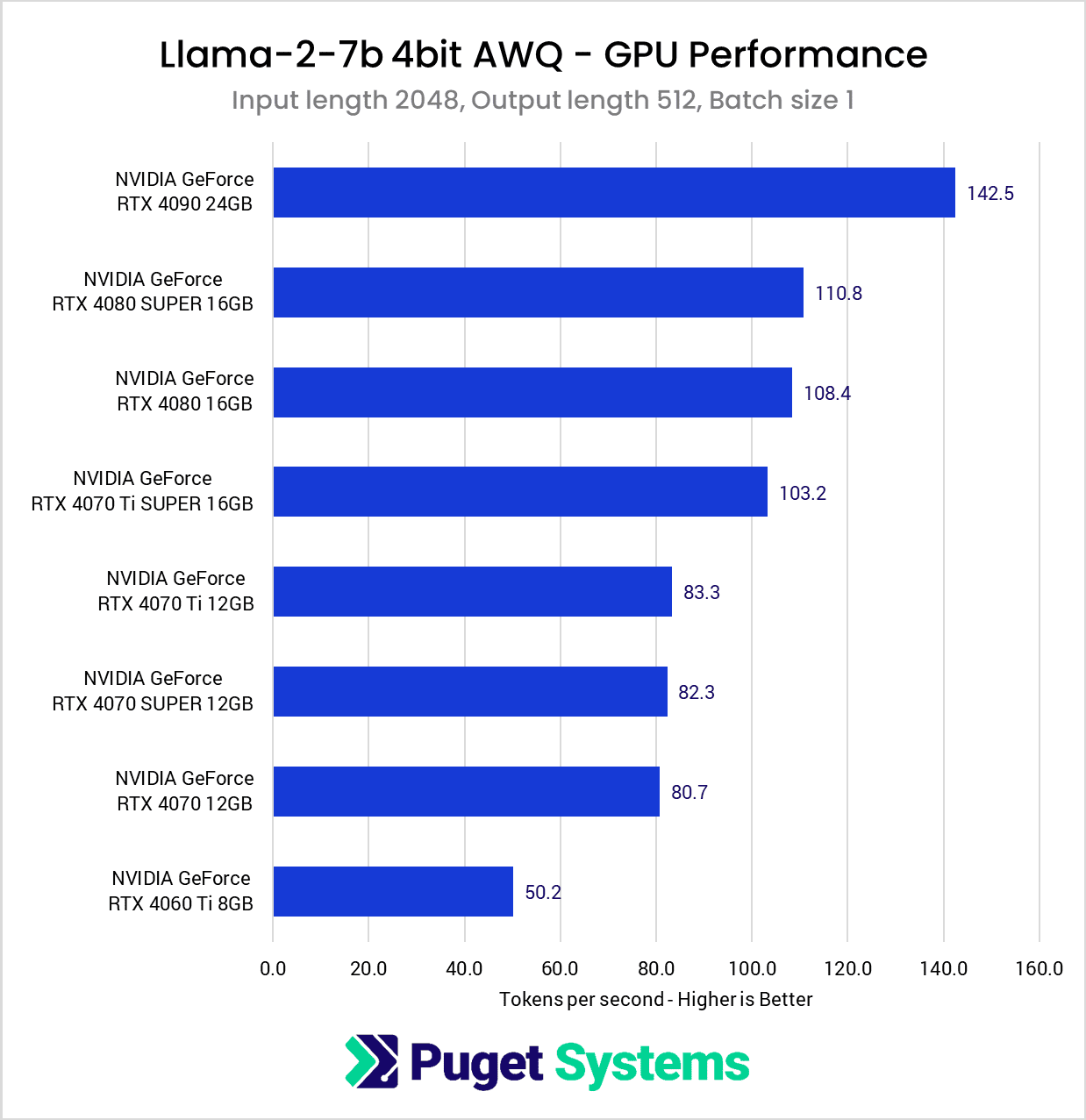
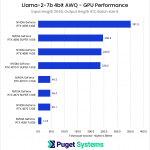
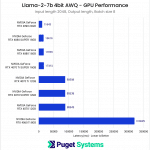
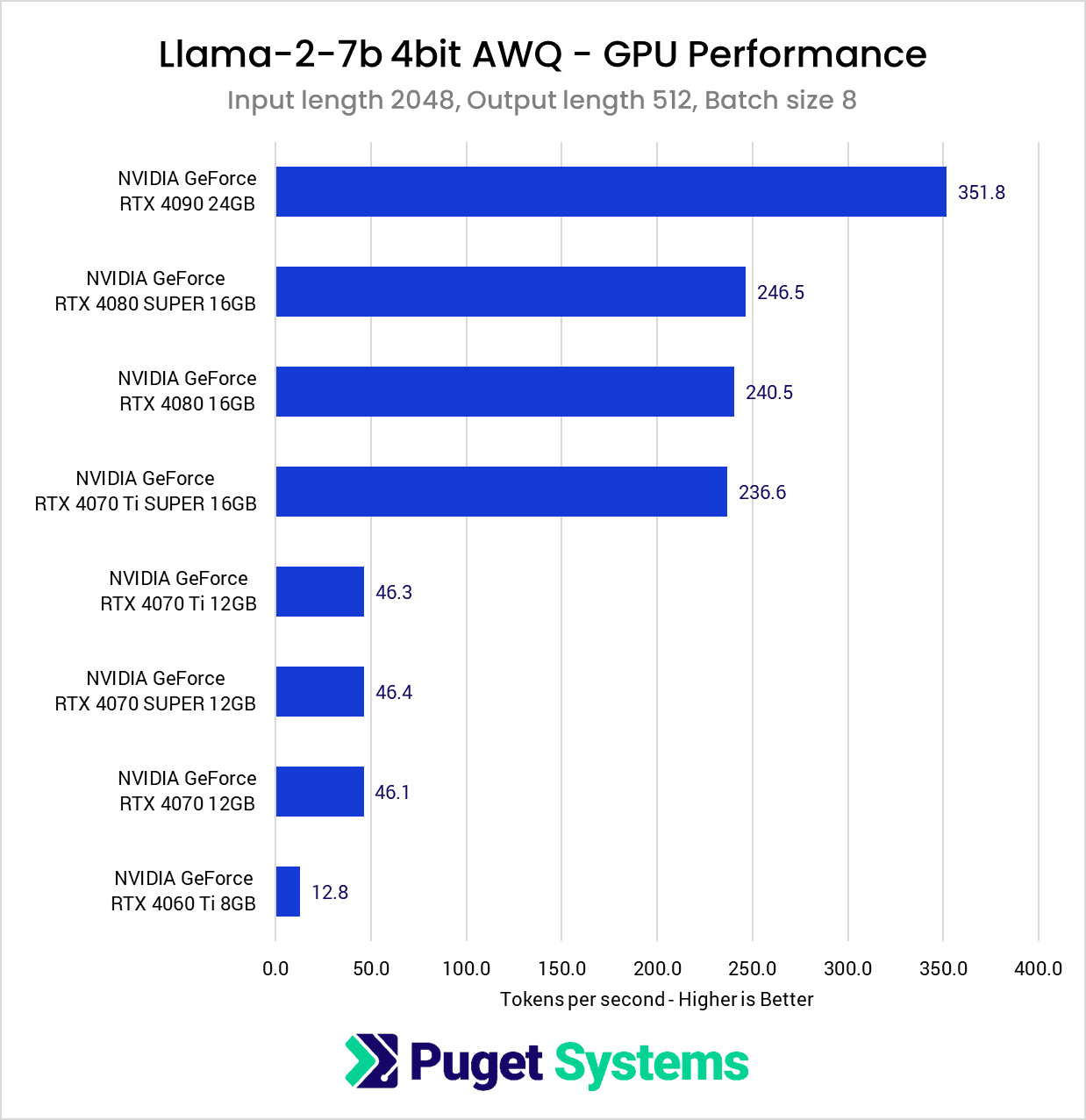
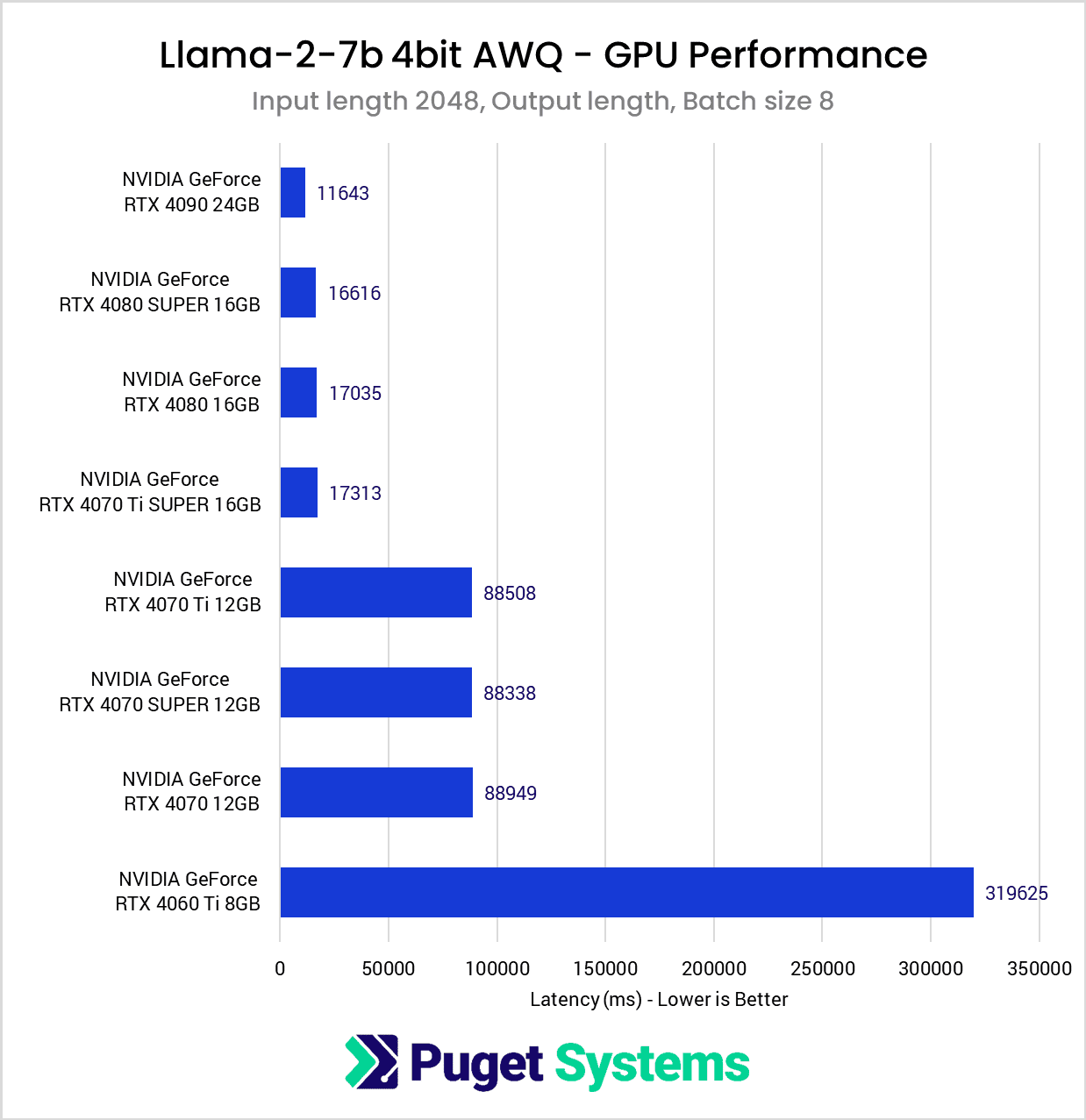
With this test, had I not finally encountered VRAM limitations, I suspect we would have seen the same pattern emerge where the larger batch size seemingly scales slightly better with Tensor Core count. The VRAM requirements for this test jumped to just over 16GB compared to the roughly 7GB of the previous tests, so we see the cards with 12GB VRAM and under struggle.
A notable factor in this test was that the tokens per second metric corresponded closely with the total time spent completing a benchmark run. The RTX 4090 completed this test in about 35 seconds, and the 16GB cards each took a little over 50 seconds. However, without sufficient VRAM, the benchmark completion time jumped to around 260 seconds for the 12GB cards and a whopping 960 seconds for the 8GB 4060Ti!
Due to driver changes NVIDIA introduced back in driver version 535.98 to resolve crashes when VRAM capacity is maxed out, instead of the benchmark failing, it overflows into the much slower system memory. This drastically impacts performance, which may or may not be preferred over a memory allocation error and a failure to run. Many Stable Diffusion users were caught off guard by this change, wondering why their performance would sometimes reach previously unseen lows. NVIDIA did implement a toggle for this behavior in the NVIDIA Control Panel, but at least in my testing for TensorRT-LLM, the “Prefer No Sysmem Fallback” global setting did not prevent the benchmark from utilizing system memory when the VRAM capacity was reached.
Closing Thoughts
Looking back on the results of the TensorRT-LLM benchmarks, it becomes clear that in addition to the raw compute power of a GPU, the memory bandwidth has an important role in overall performance. Any time that cores spend waiting for data to be fed to them is time wasted and represents a loss in overall performance. This makes it easier to understand why the GeForce RTX 4090 has been dominant relative to other consumer-oriented GPUs; its high Tensor Core count and wide memory bus are well-suited for machine learning workloads.
If I were to perform this testing again (and we likely will do so in the future!), I would like to include more “middle-ground” testing, with an input and output length of 512 and batches of 1 and 8. I think this would help establish the emerging performance patterns without exceeding the smaller GPUs’ VRAM budgets. In addition, I’m eager to see how the tool can be utilized under Linux for testing multi-GPU configurations and how NVIDIA’s Professional RTX cards perform.
Despite some limitations, such as only supporting single-GPU inference within Windows and requiring custom engines to be generated for each model and GPU combination, TensorRT-LLM is a flexible tool for deploying and testing various LLM models on NVIDIA GPUs. Whether we will implement it within our standard benchmarking suite remains to be seen, but it offers compelling reasons to consider it. Although we prefer to test in a manner that allows for multiple brands and types of GPUs to be used, there is certainly a place for brand-specific optimizations like this, especially in the AI/ML space, where those optimizations can provide significant benefits.
Image
Image Credit: NVIDIA Technical Blog – TensorRT-LLM Supercharges Large Language Model Inference on NVIDIA H100 GPUs
Looking for an AI workstation or server?
We build computers tailor-made for your workflow.
Don’t know where to start?
We can help!
Get in touch with one of our technical consultants today.