Table of Contents
Introduction
As part of our goal to evaluate benchmarks for AI & machine learning tasks in general and LLMs in particular, today we’ll be sharing results from llama.cpp‘s built-in benchmark tool across a number of GPUs within the NVIDIA RTX™ professional lineup. Because we were able to include the llama.cpp Windows CUDA binaries into a benchmark series we were already performing for other purposes, this round of testing only includes NVIDIA GPUs, but, we do intend to include AMD cards in future benchmarks.
If you’re interested in how NVIDIA’s consumer GeForce RTX GPUs performed using this benchmark and system configuration, then follow this link to check out those results. However, it’s worth mentioning that maximizing performance or price to performance are not typically the main reasons why someone would choose a professional GPU over a consumer-oriented model. The primary value propositions that both NVIDIA’s and AMD’s pro-series cards offer are improved reliability (both in terms of hardware and drivers), higher VRAM capacity, and designs more appropriate for multi-GPU configurations. If raw performance is your main deciding factor, then outside of multi-GPU configurations, a top-end consumer GPU is almost always going to be the better option.

Image
Test Setup
Test Platform
| CPU: AMD Ryzen Threadripper PRO 7985WX 64-Core |
| CPU Cooler: Asetek 836S-M1A 360mm Threadripper CPU Cooler |
| Motherboard: ASUS Pro WS WRX90E-SAGE SE BIOS Version: 0404 |
| RAM: 8x Kingston DDR5-5600 ECC Reg. 1R 16GB (128GB total) |
| GPUs: NVIDIA RTX™ 6000 Ada Generation 48GB NVIDIA RTX 5000™ Ada Generation 32GB NVIDIA RTX 4500™ Ada Generation 24GB NVIDIA RTX™ 4000 Ada Generation 20GB NVIDIA RTX™ A6000 48GB Driver Version: 552.74 |
| PSU: Super Flower LEADEX Platinum 1600W |
| Storage: Samsung 980 Pro 2TB |
| OS: Windows 11 Pro 23H2 Build 22631.3880 |
Llama.cpp build 3140 was utilized for these tests, using CUDA version 12.2.0, and Microsoft’s Phi-3-mini-4k-instruct model in 4-bit GGUF. Both the prompt processing and token generation tests were performed using the default values of 512 tokens and 128 tokens respectively with 25 repetitions apiece, and the results averaged.
GPU Performance
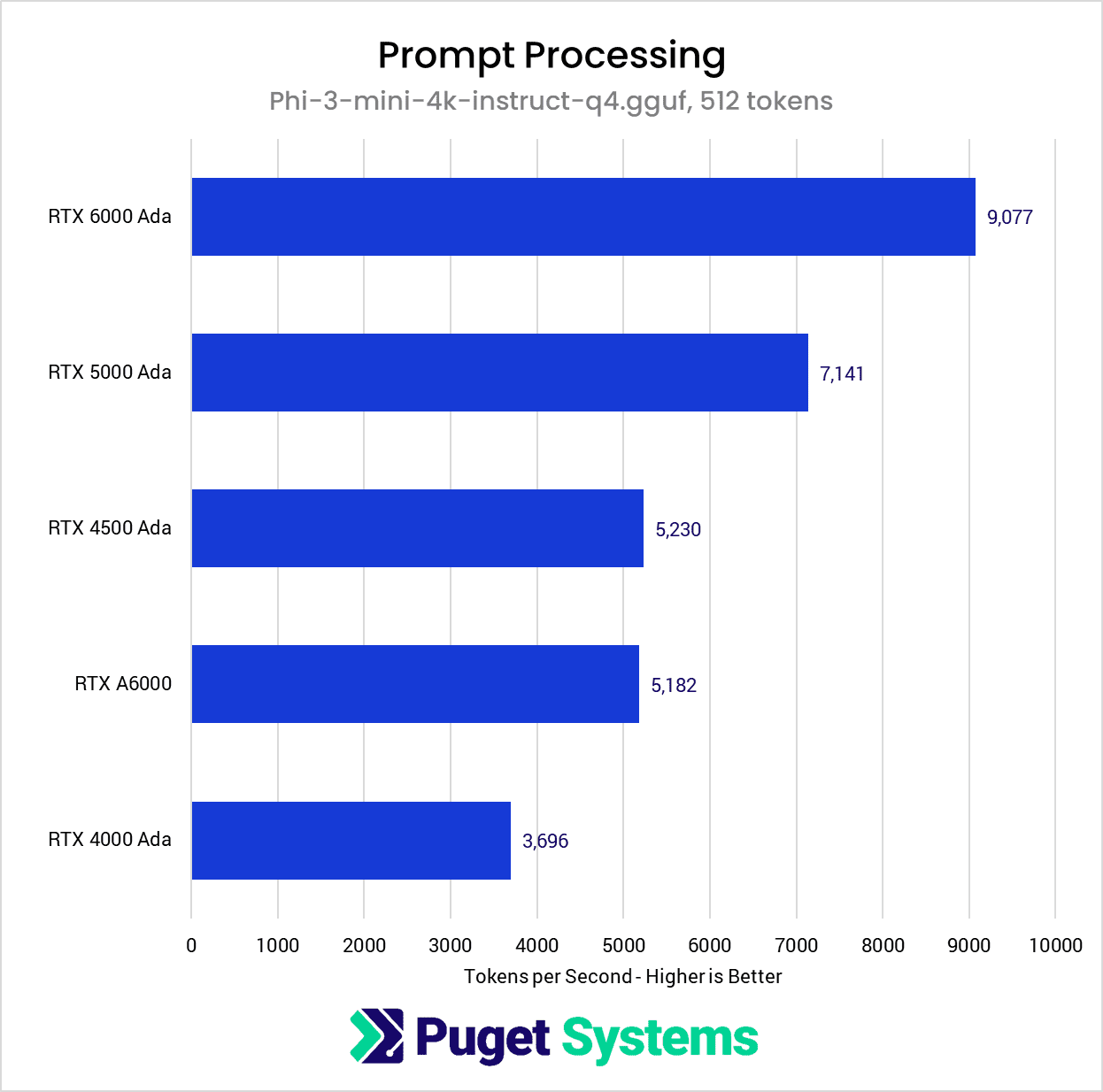
Image
Starting with the prompt processing portion of the benchmark, the NVIDIA RTX Ada Generation GPU results are not particularly surprising, with the RTX 6000 Ada achieving the top result and the RTX 4000 Ada with the lowest score. It’s interesting to see that the older RTX 6000 is essentially dead even with the RTX 4500 Ada, despite nominally being a much higher-end model.
Once we dig into the cards’ specifications (table below), the picture starts to become more clear. Here, we find that the prompt processing results track closely with the cards’ FP16 performance, which is based almost entirely upon both the number of tensor cores and which generation of tensor cores the GPUs were manufactured with. So ultimately, we find that prompt processing appears to be constrained by the compute performance of the GPU and not by other factors like memory bandwidth.
| GPU | FP16 (TFLOPS) | Tensor Core Count | Tensor Core Generation |
|---|---|---|---|
| RTX 6000 Ada Generation | 91.06 | 568 | 4th |
| RTX 5000 Ada Generation | 65.28 | 400 | 4th |
| RTX 4500 Ada Generation | 39.63 | 240 | 4th |
| RTX A6000 | 38.71 | 336 | 3rd |
| RTX 4000 Ada Generation | 26.73 | 192 | 4th |
Looking for an AI Workstation?
We build computers tailor-made for your workflow.
Don’t know where to start?
We can help!
Get in touch with our technical consultants today.
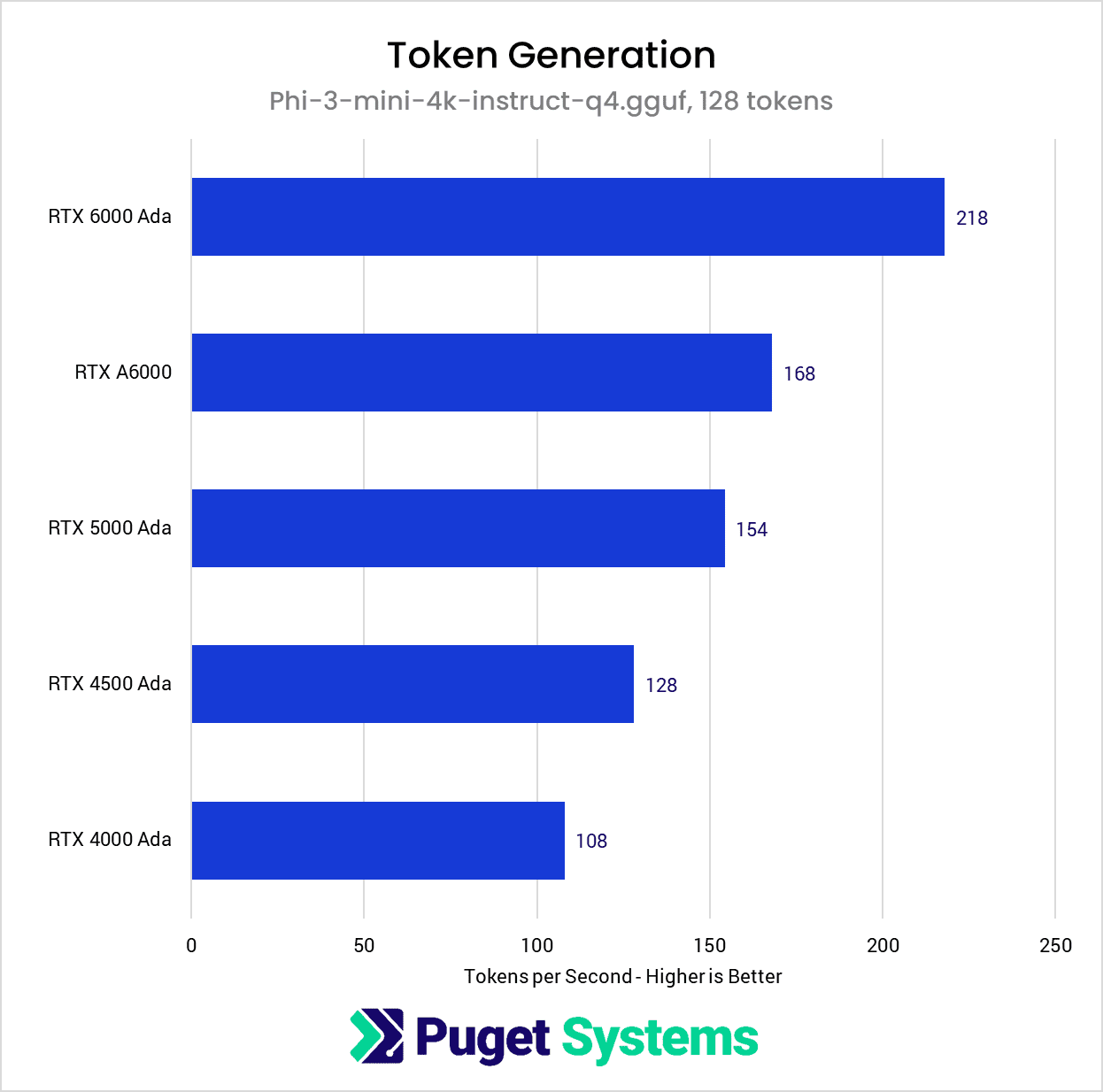
Image
In contrast to the prompt processing results, we find that token generation scales more closely with the GPUs’ memory bandwidth (table below) than tensor core count. Although the RTX 6000 Ada is still the clear winner, the older RTX A6000 is able to move up into second place, ahead of the Ada Generation models that outperformed it during the prompt processing phase of the benchmark. However, by comparing the RTX A6000 and the RTX 5000 Ada, we can also see that the memory bandwidth is not the only factor in determining performance during token generation. Although the RTX 5000 Ada only has 75% of the memory bandwidth of the RTX A6000, it’s still able to achieve 90% of the performance of the older card. This indicates that compute performance still plays a role during token generation, just not to the same degree as during prompt processing.
| GPU | Memory Bandwidth (GB/s) |
|---|---|
| RTX 6000 Ada Generation | 960 |
| RTX A6000 | 768 |
| RTX 5000 Ada Generation | 576 |
| RTX 4500 Ada Generation | 432 |
| RTX 4000 Ada Generation | 360 |
Final Thoughts
This benchmark helps highlight an important point, which is that there are several GPU specifications to consider when deciding which GPU or GPUs are the most appropriate option for use with LLMs. These results help show that GPU VRAM capacity should not be the only characteristic to consider when choosing GPUs for LLM usage. A lot of emphasis is placed on maximizing VRAM, which is an important variable for certain, but it’s also important to consider the performance characteristics of that VRAM, notably the memory bandwidth. Furthermore, beyond the specifications of the VRAM, it’s still important to consider the raw compute performance of GPUs as well, in order to get a more holistic view of how the cards stack up against each other.
This is only the beginning of our LLM testing, and we plan to do much more in the future. Larger models, multi-GPU configurations, including AMD/Intel GPU, and model training are all on the horizon. If there is anything else you would like us to report on, please let us know in the comments!
Looking for an AI and Scientific Computing workstation?
We build computers tailor-made for your workflow.
Don’t know where to start?
We can help!
Get in touch with one of our technical consultants today.